web-backup
La idea es crear una copia de seguridad de la información pública
en los portales web. La misma que sacarías haciendo scraping, pero aprovechando el tener acceso a la base de datos
para que sea mucho más rápido y eficiente.
Actualmente solo funciona para wordpress, phpbb y parcialmente mediawiki y mailman pero lo deseable es que se extienda a todos los servicios posibles. Adicionalmente busca en la configuración de apache dominios que no se hayan detectado aún.
En funcionamiento básico es el siguiente:
- Mediante un tunel
sshnos conectamos a la base de datos en el servidor - Detectamos los esquemas que nos interesan
- Construimos las consultas que extraigan la información pública
- Enriquecemos la información con:
- Obtenemos un mapa de
mailmangenerado conmailman-map.py - Buscamos en
apachemás sitios web - Creamos la base de datos
SQLitecon dicha información
Fichero de configuración y scripts
core/config.ymlcontiene la configuración para conectarse a la base de datos. Obviamente no se incluye en el repositorio, pero tienes un ejemplo con el que crear el tuyo.export.pyse conecta a la base de datos MySQL y crea la base de datosSQLiterelease.pyprepara las releases y genera:sites.7z: una copia reducida de la base de datos que generaexport.pyout/README.md: descripción y estadística básica del contenido de la base de datosout/links.txt: listado con las urls de todas las páginas recuperadas para facilitar el uso por terceros con propósitos, como por ejemplo, hacer copias enwebarchiveo descargar los portales conWebHTTrackout/links.html: listado en html con las urls
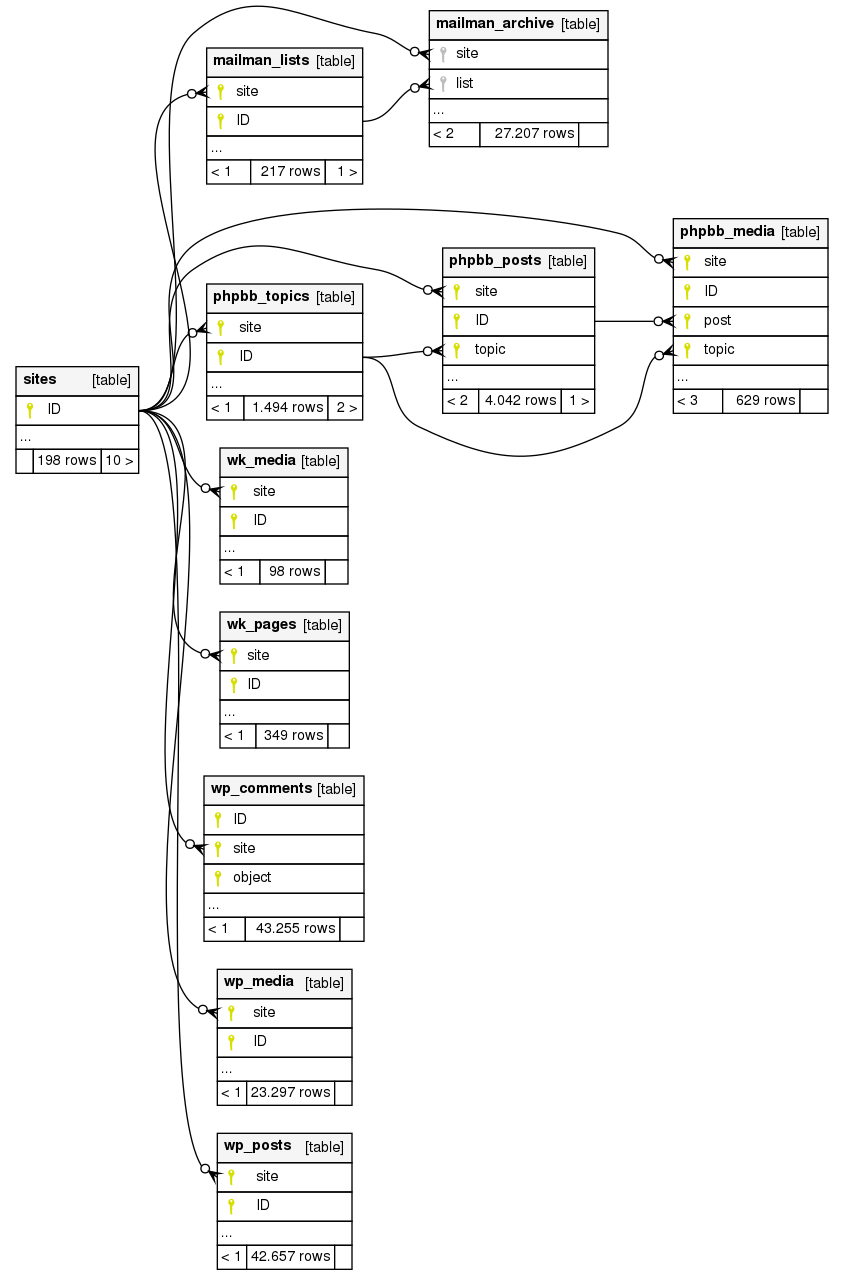
Diagrama de la base de datos SQLite